Who decide your software architecture

Software architect should select proper architecture to develop an software system. For external stakeholders and customers, it is only functional requirement. There are many factors helps to decide the architecture for an application. Let us explore the factors decide the software architecture, Architectural drivers.
Architecture requirements are not only functional requirements
Architectural drivers are formally defined as the set of requirements that have significant influence over your architecture. Architectural drivers have significant influence over the design of a system and are the determining factor over whether one design is “better” or “worse” than another that produces the same features. Architectural drivers are nearly always divided into four categories.
Architectural drivers can be one of the following.
Technical Constraints
Business Constraints
Non-Functional Requirements
High-Level Functional Requirements
Every decision for or against a certain architectural driver will have a significant impact on the resulting software system and its quality.
Technical Constraints:
Technical constraints are technical design decisions based on technical contexts such as Team skillset, Software licenses and frameworks. Here are some common examples for technical constraints:
Programming language: The chosen programming language might be dictated for a number of reasons. These may include your client’s expectations, the experience or knowledge of the development team or a restricted access to software licenses within your company.
Support of a specific platform: These constraints are often set by the client themselves. If you’re asked to build a software that will be distributed on Windows or iOS operating systems, it must of course run on these given platforms.
Use of a specific library or framework: Your company might require you to use a specific set of open source libraries or frameworks in your project, e.g. to ensure compatibility with the existing IT-infrastructure during the development process. Even though these constraints are set by business stakeholders, their effect on the project is of technical nature.
Business constraints :
Business constraints are decisions imposed by business considerations that must be satisfied in the architecture. Like technical constraints, business constraints are generally fixed from the beginning and have a significant influence on decision making for the design. Likewise once in place these are considered unchangeable. An example might be a specific delivery date, budget
Timing: Software projects usually have fixed schedules defining when a development stage should be completed or specific artifacts need to be delivered to the client. Based on this set time frame you only have a limited amount of time that can be spent debating trade-off decisions or alternative scenarios.
Budget: Similarly to timing constraints, project teams are usually bound to a specific budget by contract, which limits the number of drivers that can be invested in, necessitating compromises to be made.
Team composition: The group of team members and included participants might be fixed according to the expectations of the project’s stakeholders, e.g. an intern that has to be included for training purposes.
Non-Functional Requirements:
Non-Functional Requirements greatly influence the design of the system. There are list of non functional requirement documented in wikipedia. We have to iterate each of the attributes in the list. Mark the importance of each non-functional attribute with high, medium and low flag. It would help to decide architecture for your project. For example, performance is a common quality attribute, but performance when the system is doing what?
How fast should the function be?
How secure should the function be?
How modifiable should the function be?
Non-functional requirements need to be specific, measurable, achievable and testable if we are going to satisfy them. Most of the non-functional requirements are technical in nature and often have a huge influence on the software architecture. Understanding the non-functional requirements is a crucial part of the role, but there’s a difference between assuming what those requirements are and challenging them.
Non-functional requirement is context of application and crucial architectural driver
High-level functional requirements:
High-level functional requirements provide an overview for what the system will do, the functions and features of the system. These might take shape in any number of formats from epics to stories to use cases to ye olde “shall” statements. While quality attributes might determine specific structures you choose, the ultimate goal of the software you are building is to build achieve some bit of functionality. From an architecture perspective, you won’t go to exhaustive detail, and indeed it’s best not to go into too much detail as diving deep too early can seriously delay the project.
Once you write down all the architectural drivers, decide architecture for your application.
Developing an architecture can be seen as a process of selecting, tailoring, and combining patterns. The software architect must decide how to instantiate a pattern, how to make it fit with the specific context and the constraints of the problem.
5 Major Software Architecture Patterns
1. Microkernel Pattern
2. Microservices Pattern
3. Layered Architecture Pattern
4. Event-based Pattern
5. Space-based Pattern
You can refer each architect pattern in detail in the below link.
https://www.simform.com/software-architecture-patterns/
https://dzone.com/articles/5-major-software-architecture-patterns
Below are highlights from the above 2 reference blog.
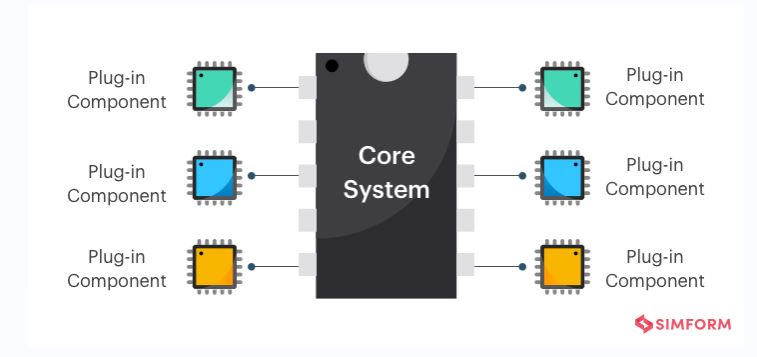
1. Microkernel Pattern:
The microkernel architectural pattern is also referred to as a plug-in architectural pattern. It is typically used when software teams create systems with interchangeable components. The microkernel architecture pattern consists of two types of architecture components: a core system and plug-in modules. Application logic is divided between independent plug-in modules and the basic core system, providing extensibility, flexibility, and isolation of application features and custom processing logic. Perhaps the best example of the microkernel architecture is the Eclipse IDE. Downloading the basic Eclipse product provides you little more than an editor. However, once you start adding plug-ins, it becomes a highly customizable and useful product.
Advantages
Great flexibility and extensibility
Some implementations allow for adding plug-ins while the application is running
Good portability
Ease of deployment
Quick response to a constantly changing environment
Plug-in modules can be tested in isolation and can be easily mocked by the core system to demonstrate or prototype a particular feature with little or no change to the core system.
High Performance as you can customize and streamline applications to only include those features you need.
Best for
Applications that take data from different sources, transform that data and writes it to different destinations
Workflow applications
Task and job scheduling applications
The applications that have a fixed set of core routines and extension modules on demand.
Disadvantages:
The plugins must have good handshaking code so that microkernel is aware of the plugin installation and is ready to work
Changing a microkernel is very difficult or even impossible if there are a number of plugins dependent on it. The only solution is to make changes in the plugins as well.
Though it is difficult to choose the right granularity for the kernel function in advance, it is even more difficult to change it in the later stage.
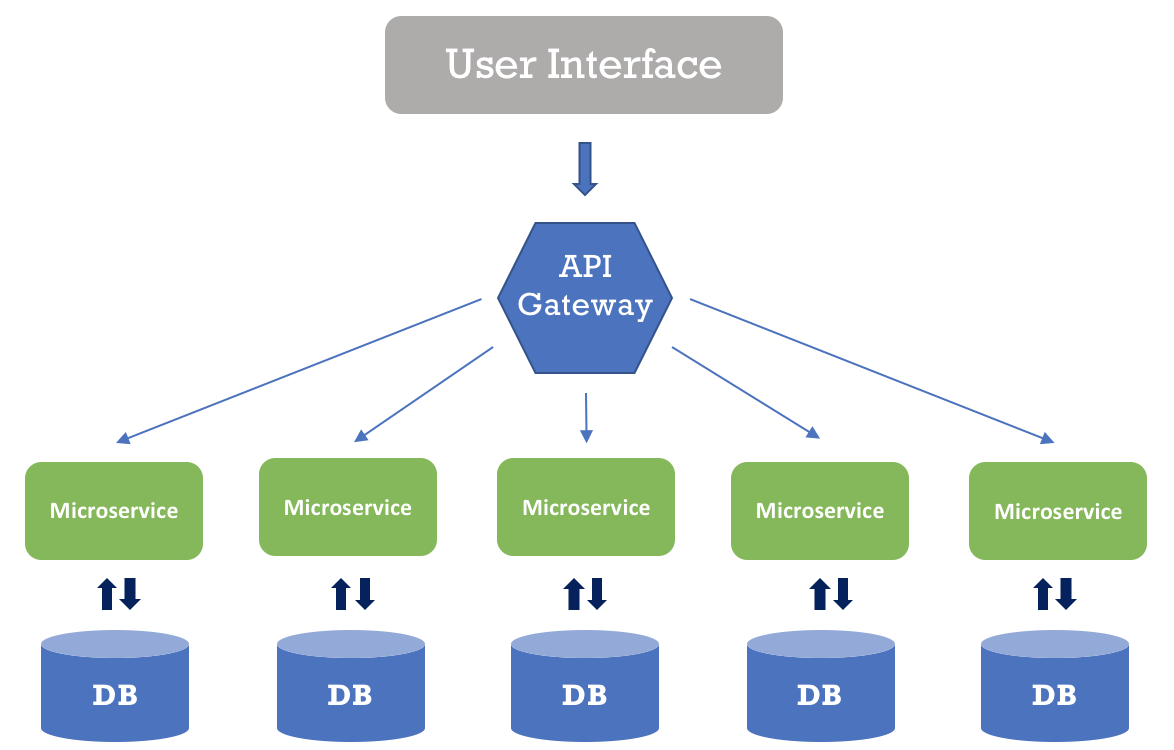
2. Microservices Pattern
A few rules for microservices
According to Fred George, they followed very specific rules for the architecture of the microservices. They started with a long session of domain modelling (about two weeks), that resulted into bounded contexts* and then into well-defined services.
Each service:
uses its own database
depends only on a message pipeline, never directly on another service
when needing something from another service, posts a message to the pipeline describing the need
periodically reads the messages from the pipeline and decide if anything needs to be done
self-monitors: if something doesn’t work, report and try to self-heal
is deployed separately
when changed, a new service instance is deployed. Once the callers switched to the new instance, the old instance can be deleted
We have found microservices to be a great idea for large projects that need to scale quickly and save money when the load increases. But they also add huge operational complexity. We’ve also seen that the most complex part of developing microservices is getting the modularity right. But teams who master modular architecture have more than one option.
Advantages
You can write, maintain, and deploy each microservice separately
Easy to scale, as you can scale only the microservices that need to be scaled
It’s easier to rewrite pieces of the application because they’re smaller and less coupled to other parts
New team members must quickly become productive
The application must be easy to understand and modify
Highly maintainable and testable – enables rapid and frequent development and deployment
Independently deployable – enables a team to deploy their service without having to coordinate with other teams
Best for:
Websites with small components
Corporate data centers with well-defined boundaries
Rapidly developing new businesses and web applications
Development teams that are spread out, often across the globe
Disadvantages:
Designing the right level of granularity for a service component is always a challenge.
All the applications don’t include tasks that can be split into independent units
Tasks that are spread between different microservices can have an adverse effect on performance
3. Layered Architecture Pattern:
This architecture pattern has gained popularity among designers and software architects alike, for it has several commonalities with the conventional arrangements of IT communications in many startups and established enterprises. The most common architecture pattern is the layered architecture pattern. Layered architecture patterns are n-tiered patterns where the components are organized in horizontal layers. This is the traditional method for designing most software and is meant to be self-independent.
Advantages
High testability because components belong to specific layers in the architecture, other layers can be mocked or stubbed, making this pattern is relatively easy to test.
High ease of development because this pattern is so well known and is not overly complex to implement, also most companies develop applications by separating skill sets by layers, this pattern becomes a natural choice for most business-application development.
Maintainable
Easy to assign separate “roles”
Easy to update and enhance layers separately
Best for:
Standard line-of-business apps that do more than just CRUD operations
New applications that need to be built quickly
Teams with inexperienced developers who don’t understand other architectures yet
Applications requiring strict maintainability and testability standards
Applications that are needed to be built quickly
Enterprise applications that require to adopt traditional IT departments and process
Those teams which have inexperienced developers who are yet not able to understand other architectures
Those applications which require strict standards of maintainability and testability
Disadvantages:
If a source code are unorganized and modules doesn’t have clear roles, it can turn into a big disaster
Sometimes the programmers skip previous layers to create tight coupling and that leads to production of logical mess full of complex interdependencies
Small modifications can require a complete redeployment of the application
4. Event-based Pattern:
This is the most common distributed asynchronous architecture used to develop highly scalable system. The architecture consists of single-purpose event processing components that listen on events and process them asynchronously. The event-driven architecture builds a central unit that accepts all data and then delegates it to the separate modules that handle the particular type. If you are looking for an architecture pattern that is agile and highly performant, then you should opt for an event-driven architecture pattern. It is made up of highly decoupled, single-purpose event processing components that asynchronously receive and process events.
Advantages
Are easily adaptable to complex, often chaotic environments
Scale easily
Are easily extendable when new event types appear
Best for:
Asynchronous systems with asynchronous data flow
User interfaces
For the applications in which individual data blocks interact with only a few modules
Disadvantage:
Testing individual modules can only be done if they are independent, otherwise they need to be tested in a fully functional system.
When several modules are handling the same events, error handling becomes difficult to structure
Development of system-wide data structure for events can become really difficult if the events have different needs
Since the modules are decoupled and independent, maintaining a transaction based mechanism for consistency becomes difficult.
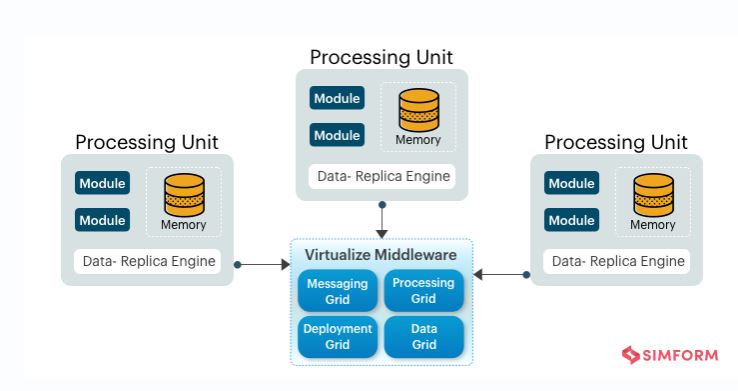
5. Space-based Pattern(Replicated environment):
The space-based architecture pattern is specifically designed to address and solve scalability and concurrency issues. It is also a useful architecture pattern for applications that have variable and unpredictable concurrent user volumes. High scalability is achieved by removing the central database constraint and using replicated in-memory data grids instead. The space-based architecture is designed to avoid functional collapse under high load by splitting up both the processing and the storage between multiple servers.
Advantages
Responds quickly to a constantly changing environment.
Although space-based architectures are generally not decoupled and distributed, they are dynamic, and sophisticated cloud-based tools allow for applications to easily be “pushed” out to servers, simplifying deployment.
High performance is achieved through the in-memory data access and caching mechanisms build into this pattern.
High scalability come from the fact that there is little or no dependency on a centralized database, therefore essentially removing this limiting bottleneck from the scalability equation.
Best for
High-volume data like clickstreams and user logs
Low-value data that can be lost occasionally without big consequences
Social networks
For the applications and software systems that work under heavy load of users
For the applications that need to address and solve scalability and concurrency issues.
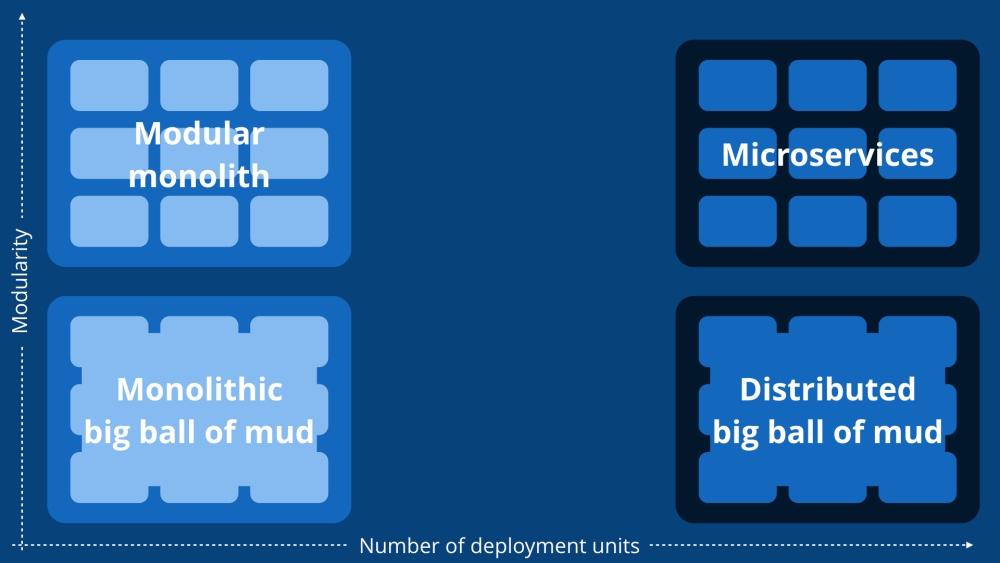
Modular Monolith: (Microservices + Monolith + Domain Driven Design)
A modular monolith or a well-thought combination between plugins, modular monoliths and libraries allow fast development while maintaining low complexity.
modular monoliths attempt to establish bounded context by segmenting code into individual feature modules. Each module exposes a programming interface definition to other modules. The altered definition can trigger its dependencies to change in turn.
There are a few scenarios that are a natural fit for modular monoliths, such as:
A greenfield implementation, such as a new peer-to-peer lending platform in the early stages of growing into a full suite of financial services.
A system with a low to moderate scale, such as a movie ticket booking platform that serves several thousand users and handles a few million transactions per week.
Non-complex business software platforms, such as a notes/documents syncing and management platform for consumer apps.
Oversized legacy applications, such as an existing large-scale banking platform monolith that needs to split into microservices, but isn’t quite ready to separate into completely independent services.